
Giving My Sitemap Some Style
Now I know I’ve talked about sitemap.xml before, but quick summary: that’s an XML file that has a list of every (public) URL on your site, to make it easier for crawlers to index your entire site since that list (or, map) lays it out. Well as an XML file, it can take XML style sheets, in a format called XSLT, short for XSL Transformations, short for eXtensible Stylesheet Language. Yes, it’s XML all the way down. But, if you’ve looked at my sitemap, you’ll see I’ve gone and done it. This is how.
So to reiterate, an XSLT file is a XML file that specifies style transformations… for another XML file.
Again, I already covered the sitemap.xml format before, so I won’t go over all that, but for this, I’ll summarize what’s required: The outermost tag is a <urlset> which contains multiple <url> tags, and each <url> has a <loc> which is the actual URL itself.
The only other piece of background information that you need is that of an XML namespace, or, XMLNS.
An XMLNS is an XML Schema (so, another XML file) that defines a particular layout and organization for an XML file.
For an XML file to conform to the sitemap schema, it needs to match the format that I just said above (plus some other things).
An XML file can identify itself as being part of that namespace with the xmlns attribute.
So, to give you a complete picture, here is a valid XSLT snippet:
|
|
XSLT can do a lot, but in this case, you can see that it’s got some HTML semantics in it.
With this XSLT, if I take a compatible XML file, and process it, I will get a valid HTML document out of it.
The stylesheet itself, in this case, defines two namespaces for use: xsl, and sitemap.
Everything in the stylesheet is part of the xsl namespace, as given by their xsl: prefixes.
I import the sitemap namespace here because the sitemap.xml file is in there.
Now, in this case, I want the styling to apply once, to the entire document.
You can have a stylesheet that does multiple things, or does things more than once, by defining multiple <template>s, that each match another part of the input document.
Since you have to have at least one, this is required.
And to just process everything, once, matching / (the entire document, in XPath terminology1) is what I use.
From here, we can just dump in HTML, as this is now part of the target output.
The only required additional transformation is to populate it, which, since the sitemap is a list of URLs, we basically need to loop over the list and output a snippet of HTML for each item.
If you’ve done some programming, you’re probably thinking of something like a for-each loop over the array.
Well, <for-each> is a valid XSLT element.
Note that, since we’re in the <template> which matched /, every relative XPath (meaning, does not start with /) is now relative to that.
So by selecting sitemap:urlset/sitemap:url (see, namespace!), this <for-each> now has a list of every <url> component in the sitemap, and the inner content of this is going to be output.
And, now that we’re in this construct, every new relative XPath is now relative to the current element it’s on.
Finally, you’ll notice that the actual content that gets repeated for each item is an HTML <li> (List Item) tag, that references both the <url>’s <loc> and <lastmod> sub-elements, with <value-of>.
If you ran this stylesheet on my sitemap (or, any sitemap), you’d get a title and a little bulleted list of every URL on the site, with its last modification date.
XSLT can get much more complicated.
And, if you’re wondering, why did I wrap the URL itself in a <code> not an <a> to actually link to itself, well, as it turns out, that’s tricky, since the location of a link (the href attribute) is an attribute, and <value-of> doesn’t work in attributes.
Until I work that out… eh.
Also yeah that’s not my stylesheet. It was, for some time, until I went in and manually built up the HTML document that my theme generates, so now it looks a little more integrated with the rest of the site, instead of everything else looking good and then there’s just a… blank white page with an unordered list. Actually, here it is:
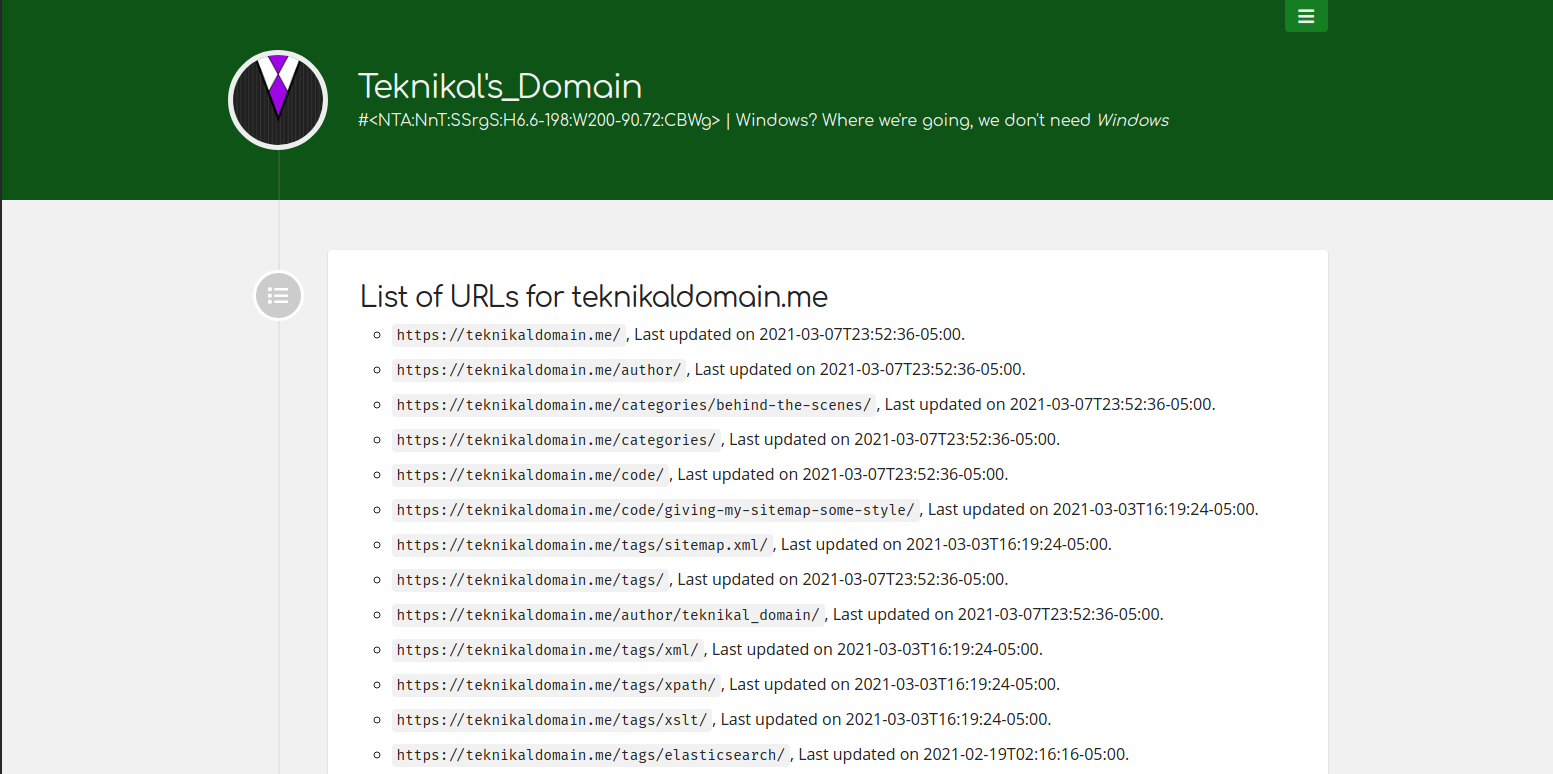
Regardless, this is the end takeaway: An XML stylesheet is something that transforms one XML document into another XML document. And that output XML document just so happens to also be perfectly valid HTML that a browser can render! So, how do we tell the browser to do all this? Well, there’s an XML directive you can use:
<?xml-stylesheet type="text/xsl" href="sitemap-style.xml" ?>
Slap this at the beginning of the sitemap, like I have, and when a browser loads the XML, since it knows that XML isn’t something that can be natively rendered like HTML, it will look for a xml-stylesheet directive, fetch the named stylesheet, and then attempt to render the output of that stylesheet, which, again, in this case, is a perfectly valid HTML document that it understands.
This is why, if you’ve ever looked at a raw XML document, you might have seen a warning like this at the top:
This XML file does not appear to have any style information associated with it. The document tree is shown below.
This is the browser saying that, without a stylesheet, it can’t make the XML “look good” so it’s just dumping the raw structure.
Now all this is cool, but here’s the really cool part: Every sitemap parser that I’ve seen doesn’t want to make the XML look good since it’s trying to actually use it.
Therefore, they disregard the stylesheet entirely, since it’s unimportant for that task!
In other words, when you type https://teknikaldomain.me/sitemap.xml into your browser, your browser wants to make it presentable, it will load the stylesheet and get some HTML to use.
When anything else, like Google tries to fetch it to use it as an actual sitemap, they’re not concerned with making it pretty, and the stylesheet is just ignored, leaving the machine with a machine-parsable XML document that complies with the spec, making it useful and still not horrible to look at.
And, since the output HTML isn’t designed to be machine-readable, I can make it slightly more presentable for humans to read, too.
-
XPath is sort of like a file path for XML, it uniquely identifies each element. For example,
/urlset/url/locis a valid XPath that, starting with the entire document, steps through the element tree, in much the same way you’d imagine with a file path, like/home/user/somefile.txt. ↩︎